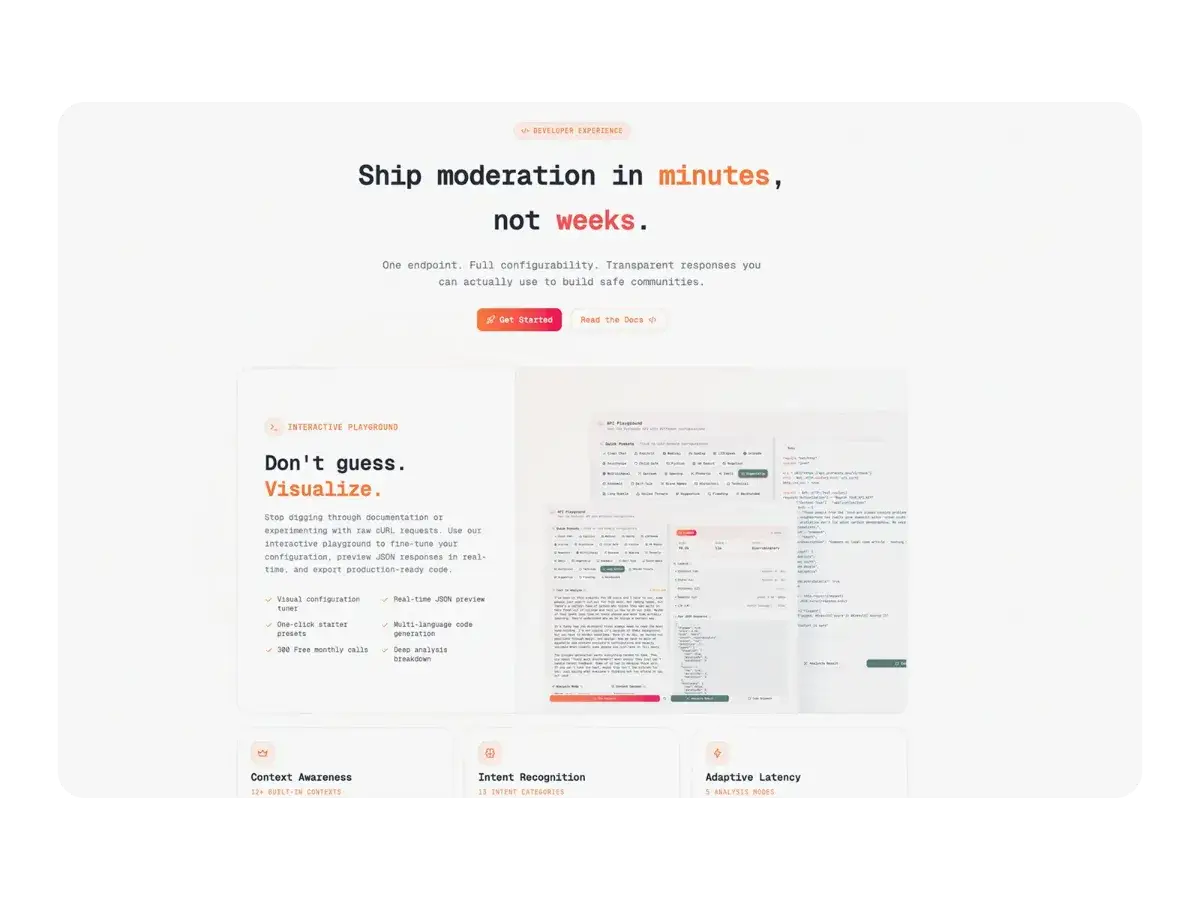
The problem with existing content moderation:
Every developer who's built profanity filtering knows the frustration. Traditional filters either flag "assistant" because it contains "ass," or miss obviously toxic content because they're just matching keywords. They can't tell the difference between "I'll destroy you in this game" (friendly trash talk) and an actual threat.
How The Profanity API solves this:
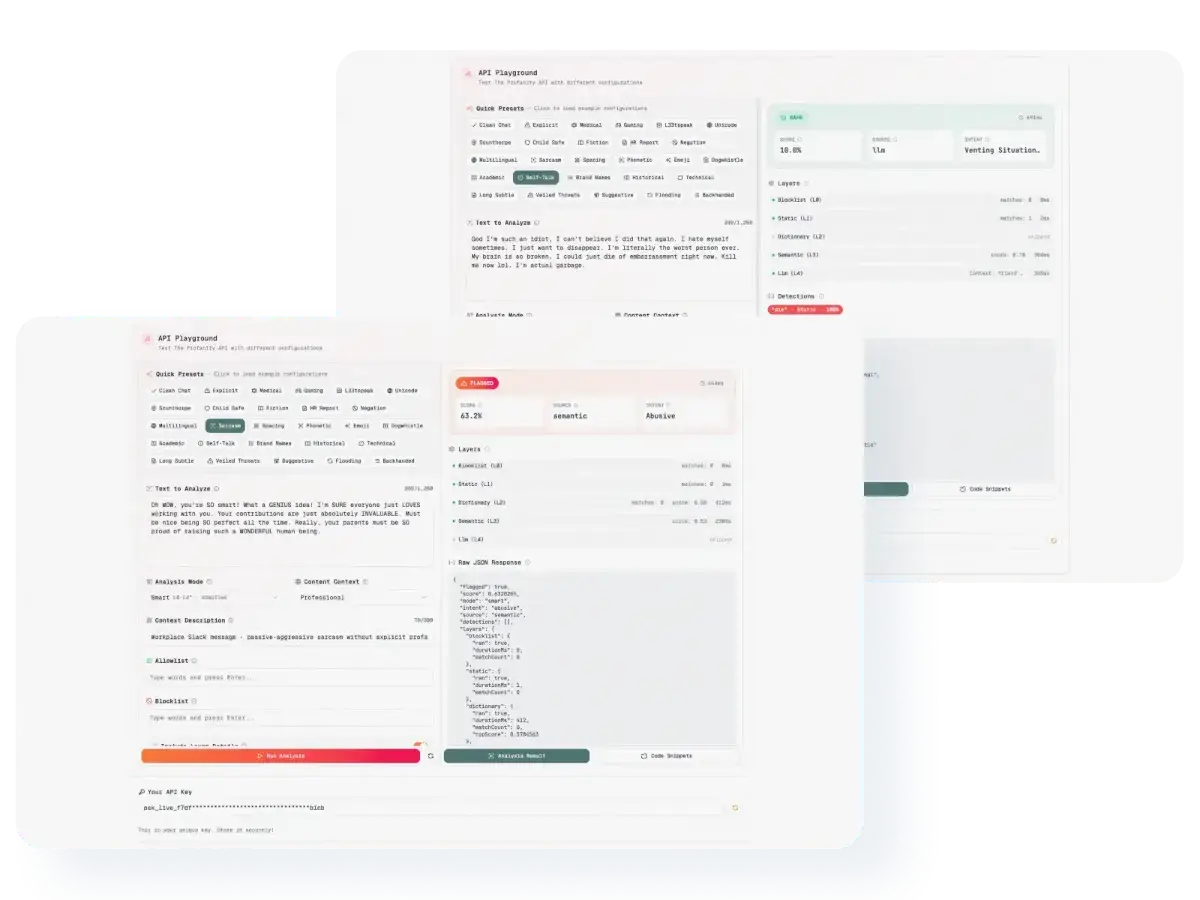
We built a 5-layer detection pipeline that analyzes content progressively:
Blocklist (L0): Your custom blocklist for instant flagging
Static (L1): Exact match against known profanity
Dictionary (L2): Semantic word matching that catches meaning, not just spelling
Semantic (L3): Phrase-level understanding for context-aware detection
LLM (L4): Human-like judgment for edge cases
The key insight: layer disagreement
When a word gets flagged by keyword matching but scores low on semantic analysis, that disagreement signals potentially innocent usage. Instead of defaulting to "block," we escalate to LLM analysis. This is how we catch "I'll kill this presentation" as safe while still flagging subtle threats.
5 analysis modes to match your needs:
instant - Blocklist + exact matching only, sub-5ms for high-volume chat
fast - Catches obfuscation attempts (f*ck, a$$hole)
balanced - Semantic + context awareness (default)
strict - Full pipeline with LLM, maximum accuracy
smart - Adaptive routing that only uses LLM when needed
12 context types for environment-aware detection:
Different environments need different standards:
Lenient contexts (higher threshold, more forgiving):
gaming - "I'll destroy you" is friendly banter
creative - Fiction, roleplay, storytelling
educational - Academic discussion of sensitive topics
medical - Clinical terminology without false positives
legal - Court documents, policy discussions
Standard contexts:
chat - Real-time messaging
comment - Comment sections
review - Product/service reviews
bio - User profiles
Strict contexts (lower threshold, less forgiving):
professional - Workplace communications
child_safe - Zero tolerance for children's platforms
username - Display names (strictest on slurs)
12 intent categories for nuanced decisions:
We don't just say "profane or not." We classify what the person is actually doing:
safe - Clean content
joking - Friendly banter, humor, gaming trash talk
venting_situational - Frustration at things, not people ("fuck this traffic!")
venting_targeted - Frustration directed at someone
passive_aggressive - Indirect hostility, backhanded compliments
discriminatory - Bias against groups (race, gender, religion, etc.)
abusive - Direct harassment, slurs, insults
threatening - Explicit or veiled threats
sexual - Sexual content, innuendo, unwanted advances
quoting - Referencing others' words or media
educational - Academic discussion of sensitive topics
professional - Medical, legal, or technical language in context
Built for developers:
RESTful API with comprehensive docs
Custom allowlist for domain-specific terms (e.g., "weed" in gardening forums)
Custom blocklist for terms you always want flagged
Optional
contextDescriptionfor LLM (like "Medical triage log from ER")includeLayersDetailsflag for debugging and transparencySmart pricing: pay base rate for standard calls, LLM surcharge only when it's actually used
Key Features:
5-layer detection pipeline: blocklist → static → dictionary → semantic → LLM
12 context types and 12 intent categories
Smart mode only runs LLM when layers disagree
Custom allowlist/blocklist per request
Detailed layer-by-layer breakdown with match positions
Sub-15ms response time in instant mode
3-1250 character limit per request
Who is this for?
Developers building chat, messaging, or social features
Gaming companies needing context-aware moderation
EdTech platforms requiring child-safe content filtering
SaaS builders adding moderation to user-generated content
Medical/legal platforms where clinical terms shouldn't trigger false positives
AI developers filtering prompts and model outputs
API Response Examples:
Simple response (balanced mode):
json
{
"flagged": false,
"score": 0.23,
"intent": "joking",
"source": "semantic",
"latencyMs": 187,
"mode": "smart",
"llmUsed": false
}With includeLayersDetails: true:
json
{
"flagged": true,
"score": 0.94,
"intent": "abusive",
"source": "llm",
"detections": [
{
"text": "idiot",
"position": { "start": 15, "end": 20 },
"confidence": 0.87,
"detectionSource": "dictionary"
}
],
"layers": {
"blocklist": { "ran": true, "durationMs": 1, "matchCount": 0 },
"static": { "ran": true, "durationMs": 3, "matchCount": 0 },
"dictionary": { "ran": true, "durationMs": 45, "matchCount": 1, "topScore": 0.87 },
"semantic": { "ran": true, "durationMs": 112, "matchCount": 0, "topScore": 0.31 },
"llm": { "ran": true, "durationMs": 340, "reasoning": "Direct insult targeting an individual" }
},
"latencyMs": 502,
"mode": "strict",
"llmUsed": true
}